
面对5000万和3000万数据量的两张表,原始查询需要15秒,看看我们如何一步步优化到1秒内完成。
一、问题背景:一个看似简单的统计需求
最近在工作中,我遇到了一个典型的SQL性能问题。业务部门需要统计某个特定日期下,特定类型项目的参与工人数量。
听起来很简单,对吧?但问题是数据量很大:
ads_table_a表:5000万+条记录,存储工人考勤数据
ads_table_b表:3000万+条记录,存储项目信息
需要根据项目表的筛选条件,找到对应项目,再去工人表统计人数。
结果:初始业务查询结果15秒,优化后结果小于1秒。
二、最初的实现:直觉写法的代价
SELECT COUNT(DISTINCT a."PROJECT_WORKER_ID")
FROM SYSDBA."ads_table_a" a
INNER JOIN (
SELECT DISTINCT "PROJECT_CODE"
FROM SYSDBA."ads_table_b" t
WHERE t."WORK_DATE" = '2025-12-11'
AND t."PRJ_STATUS" = '在建'
AND t."CATEGORY" IN ('房屋建筑工程', '市政公用工程')
AND t."AREA_CODE" LIKE '44%'
AND t."AREA_CODE" NOT LIKE '440S%'
) b ON a."PROJECT_ID" = b."PROJECT_CODE"
WHERE a."ATTENDANCE_DATE" = 20251211;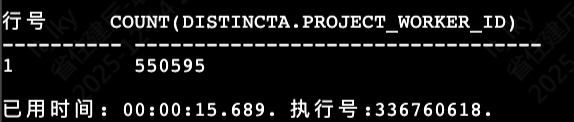
这个查询在逻辑上完全正确,但执行时间长达15秒!虽然表上已经创建了索引,但性能仍然不理想。
下面对应每个表的数据
select count(*) from SYSDBA."ads_table_a";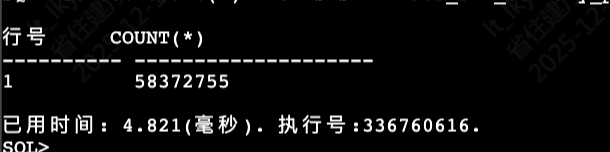
select count(*) from SYSDBA."ads_table_b";
问题分析:为什么这么慢?
在开始优化前,我们先要理解问题所在。想象一下这样的场景:
你有两本厚厚的电话簿:
一本记录了5000万人的信息(工人表)
另一本记录了3000万个项目的详细信息(项目表)
你需要先找到所有符合条件的项目(比如在特定地区、特定类型的项目),然后找出这些项目中有哪些工人,最后统计不重复的工人数量。
如果按最初的写法,相当于:
1、在3000万记录的项目表中找出符合条件的项目(几千个)
2、拿着这几千个项目编号,去5000万记录的工人表中找匹配的记录
3、统计找到的工人数量问题在于,数据库在执行时可能没有按照我们想象的最佳顺序来操作。
三、第一次尝试:临时表方案
我首先想到的是”分而治之”的策略:先把中间结果存起来,再继续处理。
DROP TABLE IF EXISTS "TEMP_PROJECTS_FILTERED";
CREATE GLOBAL TEMPORARY TABLE "TEMP_PROJECTS_FILTERED" (
"PROJECT_CODE" BIGINT PRIMARY KEY
) ON COMMIT PRESERVE ROWS;
-- 为临时表创建索引
CREATE INDEX "IDX_TEMP_PROJECTS" ON "TEMP_PROJECTS_FILTERED"("PROJECT_CODE");
-- 插入符合条件的项目(使用优化索引)
INSERT INTO "TEMP_PROJECTS_FILTERED"
SELECT DISTINCT project_code
FROM SYSDBA."ads_table_b" t
WHERE t.work_date = '2025-12-11'
AND t.prj_status = '在建'
AND t.category IN ('房屋建筑工程', '市政公用工程')
AND t.area_code LIKE '44%'
AND t.area_code NOT LIKE '440S%';
SELECT COUNT(*) FROM "TEMP_PROJECTS_FILTERED";
-- 执行查询
SELECT COUNT(DISTINCT a.project_worker_id)
FROM SYSDBA."ads_table_a" a
INNER JOIN "TEMP_PROJECTS_FILTERED" b ON a.project_id = b."PROJECT_CODE"
WHERE a."ATTENDANCE_DATE" = 20251211;
行号 COUNT(*)
---------- --------------------
1 7166
已用时间: 2.196(毫秒). 执行号:336760636.
SQL> SQL> 2 3 4 5
行号 COUNT(DISTINCTA.PROJECT_WORKER_ID)
---------- ----------------------------------
1 550595
已用时间: 00:00:03.296. 执行号:336760637.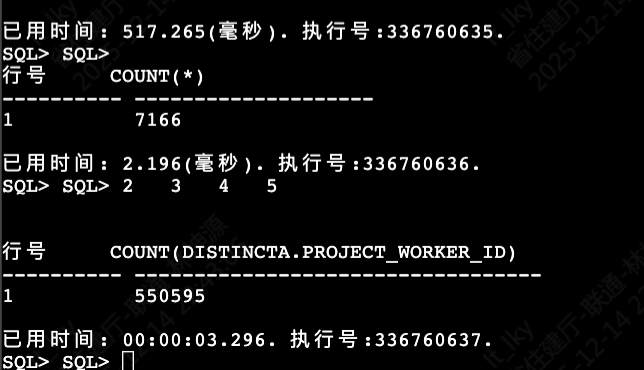
效果: 查询时间从15秒降到了5秒左右!
为什么有效?
把复杂的筛选操作拆分成两步
临时表的结果集很小(只有7166个项目),让后续关联变得简单
但是有个问题: 实际业务代码中,不允许这样拆分成多条SQL执行。我们需要一条SQL搞定所有事情。
四、第二次尝试:CTE(公用表表达式)
既然不能拆成多条SQL,那我就试试用CTE(可以理解为”临时的视图”)来实现同样的逻辑。
尝试一:直接转换(失败)
WITH filtered_projects AS (
SELECT DISTINCT project_code
FROM SYSDBA."ads_table_b" t
WHERE t.work_date = '2025-12-11'
AND t.prj_status = '在建'
AND t.category IN ('房屋建筑工程', '市政公用工程')
AND t.area_code LIKE '44%'
AND t.area_code NOT LIKE '440S%'
),
temp_counts AS (
SELECT COUNT(*) as temp_count FROM filtered_projects
),
worker_counts AS (
SELECT COUNT(DISTINCT a.project_worker_id) as worker_count
FROM SYSDBA."ads_table_a" a
INNER JOIN filtered_projects b ON a.project_id = b.project_code
WHERE a.attendance_date = 20251211
)
SELECT
t.temp_count,
w.worker_count
FROM temp_counts t, worker_counts w;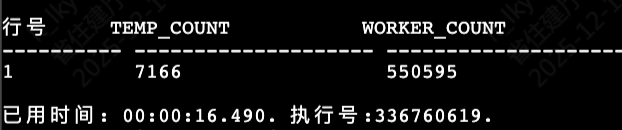
结果:又回到了15秒!CTE在这里并没有自动优化执行顺序。
三、尝试二:调整结构(部分成功)
WITH filtered_projects AS (
SELECT DISTINCT project_code
FROM SYSDBA."ads_table_b" t
WHERE t.work_date = '2025-12-11'
AND t.prj_status = '在建'
AND t.category IN ('房屋建筑工程', '市政公用工程')
AND t.area_code LIKE '44%'
AND t.area_code NOT LIKE '440S%'
),
temp_counts AS (
SELECT COUNT(*) as temp_count FROM filtered_projects
),
filtered_worker AS (
SELECT DISTINCT a.project_worker_id
FROM SYSDBA."ads_table_a" a
INNER JOIN filtered_projects b ON a.project_id = b.project_code
WHERE a.attendance_date = 20251211
),
worker_counts AS (
SELECT COUNT(*) as worker_count
FROM filtered_worker a
)
SELECT
t.temp_count,
w.worker_count
FROM temp_counts t, worker_counts w;
时间减少了,但依然未达到要求,还不够理想。我发现问题在于:数据库还是先关联了两张大表,然后再过滤。不过感觉方式是对的。所以考虑再次进行表拆分,把索引都用上,先过滤出结果再去关联表。
四、最终方案:控制执行顺序
通过前面的尝试,我意识到关键是要告诉数据库先做什么、后做什么。最终的优化方案如下:
WITH filtered_projects AS (
SELECT DISTINCT project_code
FROM SYSDBA."ads_table_b" t
WHERE t.work_date = '2025-12-11'
AND t.prj_status = '在建'
AND t.category IN ('房屋建筑工程', '市政公用工程')
AND t.area_code LIKE '44%'
AND t.area_code NOT LIKE '440S%'
),
temp_counts AS (
SELECT COUNT(*) as temp_count FROM filtered_projects
),
filtered_worker_partitioned AS (
SELECT a.project_worker_id, a.project_id
FROM SYSDBA."ads_table_a" a
WHERE a.attendance_date = 20251211
),
filtered_worker AS (
SELECT DISTINCT a.project_worker_id
FROM filtered_worker_partitioned a,
filtered_projects b WHERE a.project_id = b.project_code
),
worker_counts AS (
SELECT COUNT(*) as worker_count
FROM filtered_worker a
)
SELECT
t.temp_count,
w.worker_count
FROM temp_counts t, worker_counts w;
结果:查询时间小于1秒!
为什么最终方案这么快?
原始方案的问题:
工人表(5000万) JOIN 项目表(3000万)
↓
在30亿次可能的组合中筛选
↓
结果集巨大,统计去重耗时最终方案的思路:
第一步:项目表(3000万) → 筛选 → 7166个项目
第二步:工人表(5000万) → 按日期筛选 → 假设100万工人
第三步:7166个项目 JOIN 100万工人 → 结果集很小
第四步:统计去重 → 快速完成关键点在于先过滤、后关联,把大数据集变成小数据集再做关联。
五、最后的话
SQL优化就像解谜游戏,需要耐心和策略。记住这几个原则:
减少数据量:尽可能早地过滤掉不需要的数据
利用索引:让数据库快速找到需要的数据
控制流程:告诉数据库先做什么、后做什么