
- K-Means
定义:无监督聚类算法,将数据划分为K个互斥簇,使簇内样本相似度高,簇间差异大。
原理: - 随机初始化K个质心;
- 将每个样本分配到最近的质心(欧氏距离);
- 重新计算质心(簇内样本均值);
- 重复步骤2-3直至质心稳定。
作用:数据分群、图像压缩、异常检测。
举例:电商用户分群(按购买行为划分K类群体)。 - Huber回归
定义:鲁棒回归算法,通过损失函数平滑过渡(L1/L2),降低异常值影响。
原理:
- 损失函数:
( L_\delta(a) = \begin{cases}
\frac{1}{2}a^2 & |a| \leq \delta \
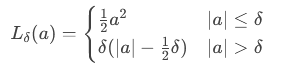
其中 a为残差,δ 为阈值。。
作用:处理含噪声/异常值的数据回归任务。
举例:房价预测(数据中存在少量极端异常价格)。
- 随机森林 (Random Forest)
定义:集成学习算法,通过多棵决策树投票提升泛化能力。
原理: - Bagging:有放回抽样生成多个训练子集;
- 特征随机性:每棵树分裂时随机选择部分特征;
- 分类任务投票/回归任务平均输出结果。
作用:分类、回归、特征重要性评估。
举例:信用卡欺诈检测(高维特征下识别异常交易)。 - XGBoost (eXtreme Gradient Boosting)
定义:基于梯度提升框架的高效Boosting算法。
原理:
- 加法模型:串行训练弱学习器(决策树),拟合残差;
- 目标函数:损失函数 + 正则化项(控制复杂度);
- 优化技术:二阶泰勒展开加速收敛、特征分桶(Histogram)。
作用:结构化数据预测(分类/回归),竞赛常用模型。
举例:Kaggle房价预测比赛(高精度回归任务)。
- LightGBM
定义:微软开发的轻量级梯度提升框架,优化效率与内存。
原理:
- GOSS (Gradient-based One-Side Sampling):保留大梯度样本,随机采样小梯度样本;
- EFB (Exclusive Feature Bundling):合并互斥稀疏特征;
- Leaf-wise生长:分裂增益最大的叶子节点(对比XGBoost的Level-wise)。
作用:大规模数据训练加速,内存占用低。
举例:广告点击率预测(十亿级样本快速训练)。
- LSTM (Long Short-Term Memory)
定义:循环神经网络(RNN)变体,通过门控机制解决长序列依赖问题。
原理:
- 遗忘门:决定丢弃哪些历史信息;
- 输入门:更新细胞状态;
- 输出门:基于当前状态输出结果。
作用:时序数据建模(如文本、语音、传感器数据)。
举例:股票价格预测(捕捉长期历史趋势)。
- 堆叠回归 (Stacking Regression)
定义:集成学习方法,组合多个基模型输出作为新特征训练元模型。
原理: - 基模型(如SVM、RF、XGBoost)在训练集上做K折交叉验证生成预测特征;
- 将基模型预测值拼接为新的训练矩阵;
- 元模型(如线性回归)基于新矩阵训练。
作用:提升预测精度,融合模型多样性。
举例:医疗诊断(组合多个模型结果提高准确性)。 - 多级融合 (Multi-level Fusion)
定义:分层融合多源数据/多阶段模型结果,增强决策鲁棒性。
原理:
- 特征级融合:拼接不同来源特征(如文本+图像);
- 模型级融合:多个模型输出加权平均或投票;
- 决策级融合:高层模型整合底层模型决策。
作用:多模态数据建模、复杂系统优化。
举例:自动驾驶系统(融合摄像头、雷达、LiDAR数据的分层决策)。
关键对比总结
| 算法 | 类型 | 核心优势 | 适用场景 |
|-||-|–|
| K-Means | 无监督聚类 | 简单高效 | 用户分群、图像分割 |
| Huber回归 | 回归 | 抗异常值 | 噪声数据建模 |
| 随机森林 | 集成学习 | 抗过拟合、特征重要性评估 | 分类/回归通用任务 |
| XGBoost | 梯度提升 | 高精度、正则化控制 | 结构化数据竞赛 |
| LightGBM | 梯度提升 | 训练速度快、内存占用低 | 大规模数据训练 |
| LSTM | 深度学习 | 长序列依赖建模 | 时序数据预测 |
| 堆叠回归 | 模型融合 | 提升泛化能力 | 高精度预测任务 |
| 多级融合 | 多模型/多源融合 | 鲁棒决策、信息互补 | 复杂多模态系统 |
通过结合算法特性与问题需求,可针对性选择或组合使用这些方法以优化结果。