
创建数据表
#--
DROP TABLE IF EXISTS `t1`;
CREATE TABLE `t1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`c1` varchar(100) DEFAULT NULL COMMENT 'c1',
`c2` varchar(100) DEFAULT NULL COMMENT 'c2',
`c3` varchar(100) DEFAULT NULL COMMENT 'c3',
`c4` varchar(100) DEFAULT NULL COMMENT 'c4',
`c5` varchar(100) DEFAULT NULL COMMENT 'c5',
`c6` varchar(100) DEFAULT NULL COMMENT 'c6',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
)ENGINE = InnoDB DEFAULT CHARACTER SET = utf8mb4 COMMENT='test';
SELECT count(*) from t1;一、多进程导入文件
import pandas as pd
import multiprocessing
import pymysql
import time
print(f'start>>>')
host = 'localhost'
user = 'root'
password = 'root'
# which database to use.
db = 'test'
filename_ = './test.csv'
# 进程数(根据cpu数量来设定)
w = 4
# 批量插入的记录数量
BATCH = 5000
# 数据库连接信息
connection = pymysql.connect(host=host, user=user, password=password, database=db)
def insert_many(l, cursor):
c_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
s = ','.join(map(str, l))
sql = f"insert into t1(id, c1, c2, c3, create_time) values {s}"
#print(f'{sql}')
cursor.execute(sql)
connection.commit()
def insert_worker(queue):
rows = []
# 每个子进程创建自己的 游标对象
cursor = connection.cursor() # 生成游标对象
while True:
row = queue.get()
if row is None:
if rows:
# 批量插入方法 或者 sql
print(f"插入{len(rows)}条")
insert_many(rows, cursor)
break
rows.append(row)
if len(rows) == BATCH:
# 批量插入方法 或者 sql
print("插入5000条")
insert_many(rows, cursor)
rows = []
def csv_test():
# 创建数据队列,主进程读文件并往里写数据,worker 进程从队列读数据
# 注意一下控制队列的大小,避免消费太慢导致堆积太多数据,占用过多内存
queue_ = multiprocessing.Queue(maxsize=100)
workers = []
for i in range(w):
# 增加进程任务
p = multiprocessing.Process(target=insert_worker, args=(queue_,))
p.start()
workers.append(p)
print('starting # %s worker process, pid: %s...', i + 1, p.pid)
dirty_data_file = r'./error.csv'
# 表字段
cols = ["id", "c1", "c2", "c3", "c4", "c5", "c6", "create_time"]
# 错误数据列表
dirty_data_list = []
reader = pd.read_csv(filename_, sep=',', iterator=True) //指定列, usecols=[2, 5, 46, 57]
#reader['create_time'] = pd.to_datetime(reader['create_time'], format='%Y-%m-%d %H:%M:%S')
loop = True
while loop:
try:
data = reader.get_chunk(BATCH) # 返回N行数据块 DataFrame类型
data_list = data.values.tolist()
for line in data_list:
#print(line)
# 记录并跳过脏数据: 键值数量不一致 或者 其他检验数据错误逻辑
# cols 表字段
#if len(line) != (len(cols) + 1):
# dirty_data_list.append(line[1:])
# continue
# 把 None 值替换为 'NULL'
clean_line = [None if x == 'NULL' else x for x in line]
#clean_line = ['nan' if x == 'NULL' else x for x in line]
#print(clean_line)
list_tmp = []
#list_tmp.append(None)
list_tmp.append(clean_line[0])
list_tmp.append(clean_line[1])
list_tmp.append(clean_line[3])
list_tmp.append(clean_line[4])
c_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
#c_time = time.strftime('%Y-%m-%d %H:%M:%S', clean_line[7])
list_tmp.append(c_time)
# 往队列里写数据
queue_.put(tuple(list_tmp))
except StopIteration:
# 错误数据写入文件
dirty_data_frame = pd.DataFrame(dirty_data_list, columns=cols)
dirty_data_frame.to_csv(dirty_data_file)
loop = False
# 给每个 worker 发送任务结束的信号
print('send close signal to worker processes')
for i in range(w):
queue_.put(None)
for p in workers:
p.join()
if __name__ == '__main__':
csv_test()二、多线程导入文件
#!/usr/bin/env python3
# encoding: utf-8
import pandas as pd
import threading
from queue import Queue
import pymysql
import time
import os
print(f'start>>>')
host = 'localhost'
user = 'root'
password = 'root'
# which database to use.
db = 'test'
filename_ = './test.csv'
# 进程数
w = 4
# 批量插入的记录数量
BATCH = 5000
# 数据库连接信息
connection = pymysql.connect(host=host, user=user, password=password, database=db)
def insert_many(l, cursor):
mutex.acquire()
c_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
s = ','.join(map(str, l))
sql = f"insert into t2(id, c1, c2, c3, create_time) values {s}"
#print(f'{sql}')
cursor.execute(sql)
connection.commit()
mutex.release()
def insert_worker(queue, thread_id):
rows = []
# 每个子进程创建自己的 游标对象
cursor = connection.cursor() # 生成游标对象
while True:
row = queue.get()
if row is None:
if rows:
# 批量插入方法 或者 sql
print(f"{thread_id}插入{len(rows)}条")
insert_many(rows, cursor)
break
rows.append(row)
if len(rows) == BATCH:
# 批量插入方法 或者 sql
print(f"{thread_id}插入5000条")
insert_many(rows, cursor)
rows = []
def csv_test():
# 创建数据队列,主进程读文件并往里写数据,worker 进程从队列读数据
# 注意一下控制队列的大小,避免消费太慢导致堆积太多数据,占用过多内存
queue_ = Queue()
workers = []
for i in range(w):
# 增加进程任务
p = threading.Thread(target=insert_worker, args=(queue_, 'thread-' + str(i)))
p.start()
workers.append(p)
print('starting # %s worker process, pid: %s...', i + 1)
dirty_data_file = r'./error.csv'
# 表字段
cols = ["id", "c1", "c2", "c3", "c4", "c5", "c6", "create_time"]
# 错误数据列表
dirty_data_list = []
reader = pd.read_csv(filename_, sep=',', iterator=True)
#reader['create_time'] = pd.to_datetime(reader['create_time'], format='%Y-%m-%d %H:%M:%S')
loop = True
while loop:
try:
data = reader.get_chunk(BATCH) # 返回N行数据块 DataFrame类型
data_list = data.values.tolist()
for line in data_list:
# 记录并跳过脏数据: 键值数量不一致 或者 其他检验数据错误逻辑
# cols 表字段
#if len(line) != (len(cols) + 1):
# dirty_data_list.append(line[1:])
# continue
# 把 None 值替换为 'NULL'
clean_line = [None if x == 'NULL' else x for x in line]
list_tmp = []
#list_tmp.append(None)
list_tmp.append(clean_line[0])
list_tmp.append(clean_line[1])
list_tmp.append(clean_line[3])
list_tmp.append(clean_line[4])
c_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
#c_time = time.strftime('%Y-%m-%d %H:%M:%S', clean_line[7])
list_tmp.append(c_time)
# 往队列里写数据
queue_.put(tuple(list_tmp))
except StopIteration:
# 错误数据写入文件
dirty_data_frame = pd.DataFrame(dirty_data_list, columns=cols)
dirty_data_frame.to_csv(dirty_data_file)
loop = False
# 给每个 worker 发送任务结束的信号
print('send close signal to worker processes')
for i in range(w):
queue_.put(None)
for p in workers:
p.join()
if __name__ == '__main__':
print(f'process id {os.getpid()}')
mutex = threading.Lock()
csv_test()本次数据模板
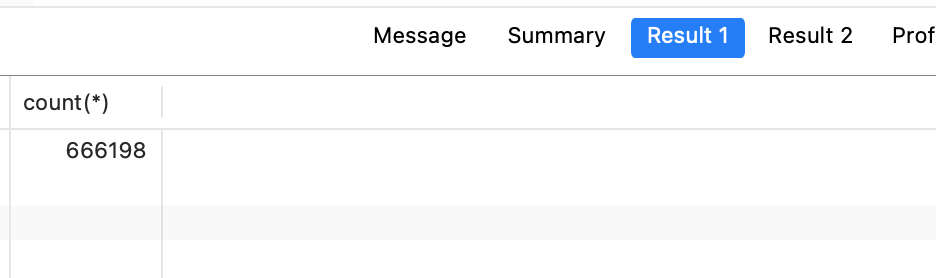
原始数量
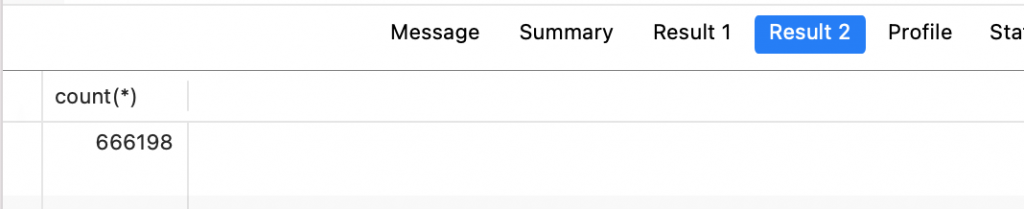
导入结果
三、优化版本
主要优化点
命令行参数支持:
新增多个命令行参数,包括:
--host:数据库地址(默认 localhost)。
--user:数据库用户名(默认 root)。
--password:数据库密码(默认 root)。
--db:数据库名称(默认 test)。
--port:数据库端口(默认 3306)。
--table:表名(默认 imported_data)。
--threads:线程数(默认 4)。
--batch-size:批量插入大小(默认 5000)。
--encoding: csv文件编码(默认utf-8)。
动态配置:
将所有可变参数(如数据库配置、表名、线程数等)通过命令行传入。
使用 argparse 模块解析命令行参数。
代码结构优化:
将数据库配置封装为字典 db_config,便于传递和管理。
将表名作为参数传递给相关函数。
默认值:
为所有命令行参数提供默认值,简化使用。源码:
#!/usr/bin/env python3
# encoding: utf-8
import pandas as pd
import threading
from queue import Queue
import pymysql
import time
import os
import argparse
from typing import List, Optional, Dict
# 默认配置
DEFAULT_HOST = 'localhost'
DEFAULT_USER = 'root'
DEFAULT_PASSWORD = 'root'
DEFAULT_DB = 'test'
DEFAULT_PORT = 3306
DEFAULT_TABLE_NAME = 'imported_data'
DEFAULT_NUM_THREADS = 4
DEFAULT_BATCH_SIZE = 5000
DEFAULT_ENCODING = 'utf-8' # 默认编码
def clean_value(value) -> Optional[str]:
"""清理数据:将 NaN 转换为 None"""
return None if pd.isna(value) else value
def infer_column_type(series: pd.Series) -> str:
"""
根据 Pandas Series 推断列的数据类型。
返回 MySQL 对应的数据类型。
"""
try:
# 尝试转换为整数
pd.to_numeric(series, downcast='integer')
return "FLOAT"
except ValueError:
try:
# 尝试转换为日期时间
pd.to_datetime(series)
return "DATETIME"
except ValueError:
# 默认使用 VARCHAR(255)
return "VARCHAR(255)"
def create_table_from_csv(csv_path: str, connection, table_name: str, encoding: str) -> Optional[List[str]]:
"""
根据CSV文件的内容生成建表语句并创建表。
返回表的列名列表。
"""
try:
# 读取CSV文件的前100行以推断列类型
df = pd.read_csv(csv_path, nrows=100, encoding=encoding)
columns = df.columns.tolist()
# 推断每列的数据类型
column_definitions = []
for col in columns:
col_type = infer_column_type(df[col])
column_definitions.append(f"{col} {col_type}")
# 生成建表语句
create_table_sql = f"CREATE TABLE IF NOT EXISTS {table_name} ("
create_table_sql += ", ".join(column_definitions) + ");"
# 执行建表语句
with connection.cursor() as cursor:
cursor.execute(f"DROP TABLE IF EXISTS {table_name};")
cursor.execute(create_table_sql)
connection.commit()
print(f"表 {table_name} 创建成功")
print(f"建表语句: {create_table_sql}")
return columns
except Exception as e:
print(f"创建表失败: {e}")
return None
def insert_many(rows: List[tuple], cursor, connection, table_name: str):
"""使用参数化查询进行批量插入"""
sql = f"""
INSERT INTO {table_name}
VALUES ({', '.join(['%s'] * len(rows[0]))})
"""
try:
cursor.executemany(sql, rows)
connection.commit()
except Exception as e:
connection.rollback()
print(f"插入失败: {e}")
def insert_worker(queue: Queue, thread_id: str, db_config: Dict, table_name: str):
"""数据库写入工作线程"""
try:
# 每个线程使用独立连接
conn = pymysql.connect(
host=db_config['host'],
user=db_config['user'],
password=db_config['password'],
database=db_config['database'],
port=db_config['port'],
autocommit=False # 使用手动提交
)
cursor = conn.cursor()
buffer = []
while True:
item = queue.get()
if item is None: # 终止信号
if buffer:
print(f"{thread_id} 插入剩余 {len(buffer)} 条")
insert_many(buffer, cursor, conn, table_name)
break
buffer.append(item)
if len(buffer) >= db_config['batch_size']:
print(f"{thread_id} 插入 {len(buffer)} 条")
insert_many(buffer, cursor, conn, table_name)
buffer = []
except Exception as e:
print(f"线程 {thread_id} 发生异常: {str(e)}")
finally:
if 'cursor' in locals():
cursor.close()
if 'conn' in locals():
conn.close()
print(f"{thread_id} 退出")
def csv_importer(csv_path: str, db_config: Dict, table_name: str, encoding: str):
"""CSV导入主逻辑"""
# 初始化队列和工作线程
queue = Queue(maxsize=10000) # 控制队列大小防止内存溢出
threads = []
# 启动工作线程
for i in range(db_config['num_threads']):
t = threading.Thread(
target=insert_worker,
args=(queue, f'Thread-{i}', db_config, table_name)
)
t.start()
threads.append(t)
print(f'启动工作线程 {i}')
# 创建数据库连接
conn = pymysql.connect(
host=db_config['host'],
user=db_config['user'],
password=db_config['password'],
database=db_config['database'],
port=db_config['port']
)
# 根据CSV文件创建表
columns = create_table_from_csv(csv_path, conn, table_name, encoding)
if not columns:
print("无法创建表,退出程序")
return
# 读取CSV并填充队列
try:
# 使用更高效的低内存模式读取
reader = pd.read_csv(csv_path, chunksize=db_config['batch_size'], iterator=True, encoding=encoding)
dirty_data = []
for chunk in reader:
# 处理数据块
for _, row in chunk.iterrows():
# 数据校验
#if row.isnull().sum() > 2: # 示例校验逻辑
# dirty_data.append(row)
# continue
# 构造插入数据
try:
data = tuple(clean_value(row[col]) for col in columns)
queue.put(data)
except Exception as e:
print(f"数据格式错误: {row},错误: {str(e)}")
dirty_data.append(row)
# 保存脏数据
if dirty_data:
dirty_data_file = os.path.join(os.path.dirname(csv_path), 'error.csv')
pd.DataFrame(dirty_data, columns=columns).to_csv(dirty_data_file, index=False, encoding=encoding)
print(f"保存脏数据到 {dirty_data_file}")
except Exception as e:
print(f"读取文件失败: {str(e)}")
finally:
# 发送终止信号
for _ in range(db_config['num_threads']):
queue.put(None)
# 等待线程结束
for t in threads:
t.join()
# 关闭数据库连接
if 'conn' in locals():
conn.close()
def main():
"""主函数"""
# 解析命令行参数
parser = argparse.ArgumentParser(description="导入CSV文件到MySQL数据库")
parser.add_argument('csv_path', type=str, help="CSV文件路径")
parser.add_argument('--host', type=str, default=DEFAULT_HOST, help="数据库地址")
parser.add_argument('--user', type=str, default=DEFAULT_USER, help="数据库用户名")
parser.add_argument('--password', type=str, default=DEFAULT_PASSWORD, help="数据库密码")
parser.add_argument('--db', type=str, default=DEFAULT_DB, help="数据库名称")
parser.add_argument('--port', type=int, default=DEFAULT_PORT, help="数据库端口")
parser.add_argument('--table', type=str, default=DEFAULT_TABLE_NAME, help="表名")
parser.add_argument('--threads', type=int, default=DEFAULT_NUM_THREADS, help="线程数")
parser.add_argument('--batch-size', type=int, default=DEFAULT_BATCH_SIZE, help="批量插入大小")
parser.add_argument('--encoding', type=str, default=DEFAULT_ENCODING, help="CSV文件编码")
args = parser.parse_args()
# 检查文件是否存在
if not os.path.exists(args.csv_path):
print(f"文件 {args.csv_path} 不存在")
return
# 数据库配置
db_config = {
'host': args.host,
'user': args.user,
'password': args.password,
'database': args.db,
'port': args.port,
'num_threads': args.threads,
'batch_size': args.batch_size
}
print(f'主进程ID: {os.getpid()}')
csv_importer(args.csv_path, db_config, args.table, args.encoding)
print('导入完成')
if __name__ == '__main__':
main()requirements.txt
pandas
pymysql操作:
首次:
python -m venv venv
venv\Scripts\activate
pip3 install -r requirements.txt
python i3.py ./test.csv --table test_table_2 --encoding gbk
再次:
venv\Scripts\activate
python i3.py ./test.csv --table test_table_2 --encoding gbk