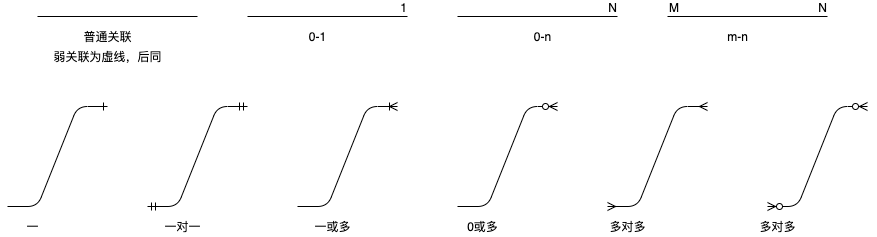
数据库除了ACID【包括原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)】特性外,还应该满足3NF。数据库三范式是关系型数据库设计中的三个标准化原则,旨在消除冗余数据,提高数据存储效率和查询性能。它们分别是第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
第一范式(1NF)
第一范式要求数据库表中的每个字段都是原子性的,即不可再分的数据项。这意味着表中的每个字段都应该是一个最小单位,不能被拆分成多个字段。
例如,在一个学生表中,姓名、年龄、性别等字段都应该是不可再分的原子数据项。
如学生表,这里包括3个信息,应该设计为3个字段
| 学生 |
| 张三,18,男 |
| 李四,17,女 |
| 王五,18,男 |
应该这样设计
| 姓名 | 年龄 | 性别 |
| 张三 | 18 | 男 |
| 李四 | 17 | 女 |
| 王五 | 18 | 男 |
第二范式(2NF)
在满足第一范式的基础上,第二范式要求表中的非主键字段必须完全依赖于主键,不能只依赖于主键的一部分。
例如,在一个学生成绩表中,学生ID和课程ID联合作为主键,成绩字段必须完全依赖于这两个ID的组合,而不能只依赖于其中一个ID。
如学生对应的成绩,这里包括每个人对应各科的成绩
| 姓名 | 年龄 | 性别 | 课程 | 分数 | 班级 |
| 张三 | 18 | 男 | 语文 | 90 | 高三(1)班 |
| 张三 | 18 | 男 | 数学 | 88 | 高三(1)班 |
| 张三 | 18 | 男 | 英语 | 98 | 高三(1)班 |
| 李四 | 17 | 女 | 语文 | 99 | 高三(2)班 |
| 李四 | 17 | 女 | 数学 | 72 | 高三(2)班 |
| 李四 | 17 | 女 | 英语 | 92 | 高三(2)班 |
| 王五 | 18 | 男 | 语文 | 78 | 高三(3)班 |
| 王五 | 18 | 男 | 数学 | 100 | 高三(3)班 |
| 王五 | 18 | 男 | 英语 | 56 | 高三(3)班 |
应该这样设计
| id | 姓名 | 年龄 | 性别 | 班级 |
| 1 | 张三 | 18 | 男 | 高三(1)班 |
| 2 | 李四 | 17 | 女 | 高三(2)班 |
| 3 | 王五 | 18 | 男 | 高三(3)班 |
| id | 课程 |
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英语 |
| 用户ID | 课程ID | 分数 |
| 1 | 1 | 90 |
| 1 | 2 | 88 |
| 1 | 3 | 98 |
| 2 | 1 | 99 |
| 2 | 2 | 72 |
| 2 | 3 | 92 |
| 3 | 1 | 78 |
| 3 | 2 | 100 |
| 3 | 3 | 56 |
这个设计只满足了2NF,如果需要满足3NF,还需要把班级表进行拆分。
第三范式(3NF)
第三范式进一步要求非主键字段只能依赖于主键,而不能依赖于其他非主键字段。这意味着表中的字段之间不能存在传递依赖关系。
接2NF的例子。应该拆分为4个表,这样才满足3NF的设计。
| id | 姓名 | 年龄 | 性别 | 班级ID |
| 1 | 张三 | 18 | 男 | 1 |
| 2 | 李四 | 17 | 女 | 2 |
| 3 | 王五 | 18 | 男 | 3 |
| id | 课程 |
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英语 |
| id | 班级 |
| 1 | 高三(1)班 |
| 2 | 高三(2)班 |
| 3 | 高三(3)班 |
| 用户ID | 课程ID | 分数 |
| 1 | 1 | 90 |
| 1 | 2 | 88 |
| 1 | 3 | 98 |
| 2 | 1 | 99 |
| 2 | 2 | 72 |
| 2 | 3 | 92 |
| 3 | 1 | 78 |
| 3 | 2 | 100 |
| 3 | 3 | 56 |
常用数据库建模线条